
Python + TensorFlow で機械学習環境を構築してネコちゃんとワンちゃんの写真分類を動かしてみよう
はじめに
Python機械学習について興味あるけど何から手をつけて良いかわからないという人も少なくないのではと思います。まさに今の自分がそうです。
学習のためにもまずは Jupyter Notebookを利用してPython機械学習の実行環境を構築してみます。
さらに機械学習ライブラリである TensorFlow を導入し、チュートリアルに沿って、ネコちゃんとワンちゃんの画像分類を動かしてみます。
ちなみに私はネコちゃん派です。可愛いは正義!
環境
Mac OS 10.14.6
Jupyter Notebookインストール
Jupyter NotebookというOSSを利用することで、Pythonをブラウザで実行でき、データを視覚化できたりと簡単に環境が作れるので便利です。
Anaconda インストーラーを使用するのが簡単なので、こちらを使用してインストールします。
Anacondaダウンロードページから、MacOSの 「64-bit Graphical installer」を選択し、インストーラーをダウンロードします。
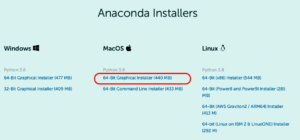
ダウンロードした「Anaconda3-2021.05-MacOSX-x86_64.pkg」を実行し、Anaconda をインストールします。
Jupyter Notebook起動してみる
Jupyter Notebook起動
上記でインストールした Anaconda 起動します。
アプリケーションに緑の輪のようなアイコンの 「Anaconda Navigator」というものが 追加されています。この「Anaconda Navigator」を起動します。

起動すると下記のような画面が立ち上がります。
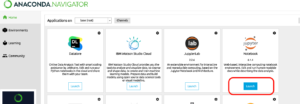
Jupyter Notebook の欄にある「Lanch」ボタンを押下すると Jupyter Notebookが起動します。ホームディレクトリが表示されます。

ファイル作成
ファイル作成は、右端にある「New」のところをクリックし、Notebook Pythonを選択します。

そうすると、新たにブラウザが立ち上がります。
入力のところにコード書いて「実行」ボタンをクリックすれば、コードが実行できます。
作成したファイルの拡張子は「.ipynb」です。
Jupyter Notebook終了
ファイル編集画面を終了するには、必ず「Fileメニュー => 閉じて終了(Close and Halt)」で終了しましょう。
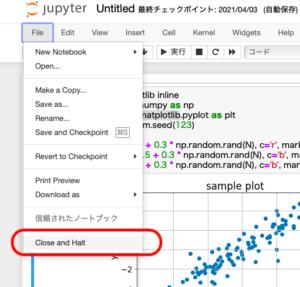
「x」でブラウザ閉じてしまうと、ゾンビプロセスが残ってしまうこともあるので、上記手順で終了します。
あとはJpyter NotebookのMain画面に戻り「終了(Quit)」をクリックすることでJupyter Notebook自体も終了します。
TensorFlow を Jupyter Notebook へ導入
TensorFlowとは、ディープラーニングアルゴリズムを実行することができるライブラリです。ニューラルネットワークモデルの作成、トレーニング実施、評価、予測などを効率よく行うことができる人気の高いディープラーニングツールです。
今回は、この TensorFlow を導入し、実際に動かしてみます。
Jupyter Notebook にはデフォルトのBase(root)環境だと TensorFlow はインストールされていないようです。なので、個別でインストールする必要があります。
新規Python環境作成
Anaconda Navigatorの「Environments」メニューの「Create」をクリックしてBase (root) とは別のPython環境を作成します。
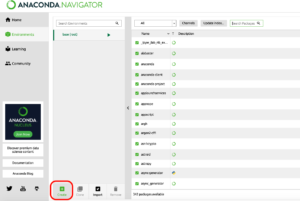
名前はわかりやすく「TensorFlow」にしました。
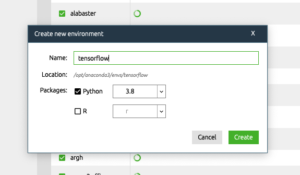
この環境に TensorFlow をインストールします。
TensorFlowインストール
作成した TensorFlow 環境の実行ボタン風のところをクリックし、「Open terminal」をクリックします。
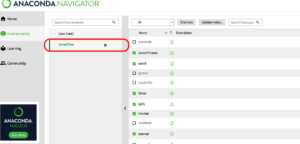
そうするとターミナルが立ち上がります。
表示されたターミナルにて、TensorFlowインストール方法方法の通り、pipコマンドで TensorFlow をインストールします。
$ pip install --upgrade pip
Requirement already satisfied: pip in /opt/anaconda3/envs/tensorflow/lib/python3.8/site-packages (21.1.3)
(tensorflow) casareal:~ casareal
$ pip install tensorflow
Collecting tensorflow
Downloading tensorflow-2.5.0-cp38-cp38-macosx_10_11_x86_64.whl (195.7 MB)
|████████████████████████████████| 195.7 MB 58 kB/s
Collecting tensorflow-estimator<2.6.0,>=2.5.0rc0
Downloading tensorflow_estimator-2.5.0-py2.py3-none-any.whl (462 kB)
|████████████████████████████████| 462 kB 385 kB/s
〜省略〜これで TensorFlow がインストールできました。
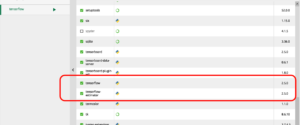
Matplotlibインストール
Matplotlibとは、グラフ描画ライブラリです。棒グラフや散布図、画像ファイルも描画でき、学習の精度や損失から評価結果まで視覚化できるので、TensorFlow と一緒に入れておくと便利です。
新しく作成した環境では、Matplotlibも「installed」 になっていなかったのでインストールします。
All で検索すると、Matplotlib系のものが出てくるのでどちらもApplyしておきます。
これで実行環境は整いましたね!
いざ TensorFlow を動かすぞ!
それでは実際に TensorFlow のコードをチュートリアルを元に、TensorFlow の高レベル APIである tf.keras を使用し、事前にトレーニング済みのMobileNetV2モデル からベースモデルを作成し、cats_and_dogsデータセットを利用してネコちゃんとワンちゃんの画像分類を動かしてみましょう。
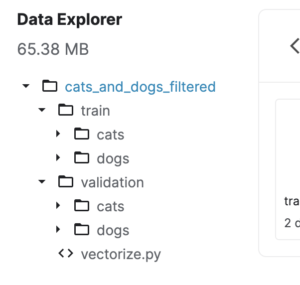
cats_and_dogs_filtered.zipファイルの中身は下記のようになっています。
入力のところに下記コードを設定し、実行します。
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
# 画像ファイル含むデータセットダウンロード
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
# 訓練データディレクトリ設定
train_dir = os.path.join(PATH, 'train')
# 検証データディレクトリ設定
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
# 訓練データセット作成
train_dataset = image_dataset_from_directory(train_dir,shuffle=True,batch_size=BATCH_SIZE,image_size=IMG_SIZE)
# 検証データセット作成
validation_dataset = image_dataset_from_directory(validation_dir,shuffle=True,batch_size=BATCH_SIZE,image_size=IMG_SIZE)
# 検証データセットから確認用のデータセットを用意
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
# 画像ファイルをランダムで反転させてデータ拡張
data_augmentation = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),
])
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset= -1)
# 事前にトレーニングされた大規模データセットであるMobileNetV2モデルからベースモデルを作成する
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
# このベースモデルを、特微抽出として使用する
# ベースモデルをフリーズさせて、トレーニング中にレイヤーの重みが更新されないようにする
base_model.trainable = False
# ベースモデルのアーキテクチャを出力
base_model.summary()
# 特微から予測を生成する
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
# denseレイヤー適用して、特微を画像ごとに一つの予測として変換する
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
# モデル構築
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
# モデルコンパイル
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# モデルのアーキテクチャを出力
model.summary()
len(model.trainable_variables)
initial_epochs = 10
# モデルトレーニング
loss0, accuracy0 = model.evaluate(validation_dataset)
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
# ベースモデルのフリーズを解除
base_model.trainable = True
print("Number of layers in the base model: ", len(base_model.layers))
# 精度アップのため微調整
fine_tune_at = 100
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
# 微調整後、再度モデルコンパイル
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(lr=base_learning_rate/10),
metrics=['accuracy'])
# モデルのアーキテクチャを出力
model.summary()
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
# 精度アップのためモデルのトレーニングを続ける
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
# 確認用データセットから画像のバッチを取得
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
# 確認用データセットから予測値を取得
predictions = model.predict_on_batch(image_batch).flatten()
#モデルはロジットを返すので、シグモイドに変換
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
# 確認用データセットの評価と予測を表示する
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")実行が完了すると、下記のように確認用データセットから9枚画像ファイルをピックアップして、ネコちゃんかワンちゃんかを分類した結果が表示されます。
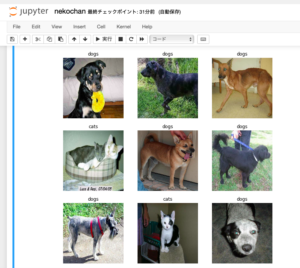
写真とラベルを見ると、ネコちゃんかワンちゃんかが判別されていますね!
以上で、Python + TensorFlow の実行環境構築と動作確認できました。