
Javaの文字列比較はequalsでいいの?
こんにちは!
カサレアルでJavaのコースを担当している櫻庭です。
Javaで文字列の比較を行う場合、equalsメソッドを使用しましょうという解説がよくされていますが、ほんとそれでいいのでしょうか?
結論を先に書いてしまうと、間違いではないけれど、十分ではないです。
このエントリーでは、文字列比較にequalsメソッドが十分ではない解説をしていきます。
Unicodeにおける文字の比較
文字列が英数字(いわゆるLatin-1)の範囲に収まっているのであれば、文字列の比較にequalsメソッドを使うの問題ありません。
しかし、英数字を超える文字範囲では、これが正しいとは限りません。たとえば、次の2つのファイルの内容を比較することを考えてみましょう。
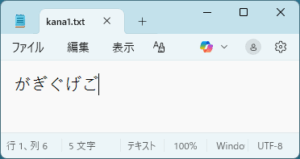
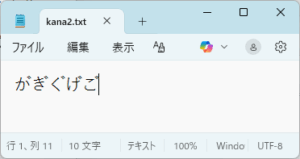
この2つのファイルの内容を次のプログラムで比較してみましょう。
void main() throws IOException {
var content1 = Files.readString(Path.of("kana1.txt"));
var content2 = Files.readString(Path.of("kana2.txt"));
IO.println(content1.equals(content2));
}このプログラムはJava 25で記述しているので、メインクラスとインポート文は省略しています。また、System.outではなく、Java 25で導入された新しいjava.lang.IOクラスも使用しています。
これらのJava 25の機能については Java 25の初心者向け機能 をご覧ください。
では、実行してみます。
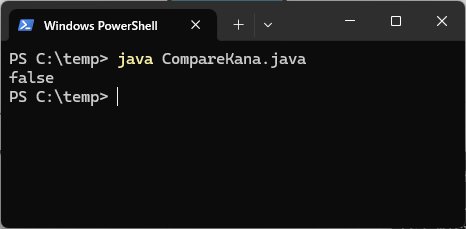
結果はfalseになってしまいました。
kana1.txtとkana2.txtは見た感じではまったく同じですが、なぜequalsメソッドの返り値がfalseになってしまったのでしょう?
実は、これはUnicodeの結合文字を使っているからなのです。
結合文字
Unicodeにはさまざまな特徴があります。そのうちの1つに結合文字があります。これは1つの文字を2つ以上の文字コードで表している文字のことです。
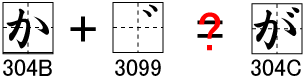
たとえば、「が」を表すために「か」と濁点を組み合わせて作るような文字のことです。
Unicodeでは「か」はU+304B、濁点はU+3099なので、U+304B U+3099の2つの文字コードで「が」を表すことができます。
このような結合文字はアルファベットに発音区別符号などを組み合わせる場合(äやõなど)や、絵文字を組み合わせる場合などに使われています。
ここで問題になるのは、文字を結合させて表す文字に、1つの文字コードで表せる文字(これをUnicodeでは合成済み文字と呼びます)が多くあるということです。たとえば、「が」は結合文字としても表せますが、U+304Cという単独の文字コードでも表すことができるのです。
先ほどのノートパッドの画像の下部に文字数が表示されています。気がつかれた方もいらっしゃると思いますが、その文字数がkana1.txtは5文字、kana2.txtでは10文字になっています。つまりkana1.txtは合成済み文字、kana2.txtは結合文字で表していたのです。
この2つの表し方は見た目は同じです。さて、これは等しいと考えますか?それとも異なると考えますか?
文字としては同じものなので、文字コードは異なっていても同じものとして扱いたいですよね。このような結合文字と合成済み文字のように、同じものとして扱える文字をUnicodeの言葉で正規等価(Canonical Equivalence)と呼びます。
このため正規等価の文字が等しいかどうかを調べるには、文字を正規化してから行う必要があります。
文字列の正規化
正規等価の文字を比較するための正規化には2種類の形式があります。
- 正規分解 Normalize Form Decomposite (NFD)
- 正規合成 Normalize Form Composite (NFC)
正規分解は、合成済み文字を分解して結合文字で表す正規化です。たとえば、「が」を表すU+304Cを、U+304B U+3099に分解します。
これとは逆に、正規合成は結合文字を合成済み文字に置き換える正規化です。U+304B U+3099をU+304Cに置き換えます。
Javaではこの正規化を行うためにはjava.text.Normalizerクラスのnormalizeメソッドを使用します。
normalizeメソッドの引数は2つです。第1引数は正規化を行う文字列、第2引数が正規化の形式を表す列挙型のNormalizer.Formを指定します。そして、戻り値が正規化した文字列になります。
では、先ほどの比較のプログラムを正規化してから比較するように変更してみましょう。
void main() throws IOException {
var content1 = Files.readString(Path.of("kana1.txt"));
var content2 = Files.readString(Path.of("kana2.txt"));
// 文字列の正規化 - 正規合成NFCを使用
var normalizedContent1 = Normalizer.normalize(content1, Normalizer.Form.NFC);
var normalizedContent2 = Normalizer.normalize(content2, Normalizer.Form.NFC);
IO.println(normalizedContent1.equals(normalizedContent2));
}では、実行してみましょう。
正規化後の文字列は等しいという結果になりました。
ここでは、NFCを用いましたが、もちろんNFDでも同じ結果になります。
まとめ
Javaは文字の内部表現としてUnicode (正確にはUTF-16)を使用しています。このため、Unicodeの結合文字などの特徴がそのまま内部表現として使われます。
したがって、文字列の等価性を調べるには、まず文字列を正規化してから、equalsメソッドで比較する必要があります。
このことが、文字列の比較する時にequalsメソッドだけでは不十分という理由です。
これはJavaだけではなく、文字の内部表現としてUnicodeを使用している言語でも同じです。Unicodeの正規等価を考慮しないと、文字列の比較で間違った結果を返してしまうことがあるのです。
ところで、全角カナの「ア」と半角カナの「ア」は同じとみなしますか?
これは、正規等価とはまた異なった等価性の問題です。これについてはまた別のエントリーで紹介したいと思います。
カサレアルでは、Javaを学ぶ方に向けて「Javaプログラミング入門」や「Javaプログラミング基礎」などのコースを開催しています。
Javaに関するコースの詳細や開催日程に関しては以下のリンクをご覧ください。
バックエンド開発を学ぶ研修一覧
https://www.casareal.co.jp/ls/service/openseminar/search/backend
About skrb
Java歴30年。 今でもJavaを使い続けています。