PythonでWebスクレイピングを学ぶ
はじめに
この記事では、Pythonを用いてWEBスクレイピングを学ぶことを目的として、環境構築から実際にWEBスクレイピングをするまでの手順をまとめました。
Anacondaというツールを使う方法もありましたが、
今回は勉強を兼ねているので一から順にやっていこうと思います。
用意した環境
- OS: Windows10
- Python: 3.9.6
環境構築
インストール
まずPython公式のWindows用のダウンロードページを開いて、インストール用のファイルのダウンロードをします。
赤枠の部分を押下していくとインストールファイルがダウンロードできました。


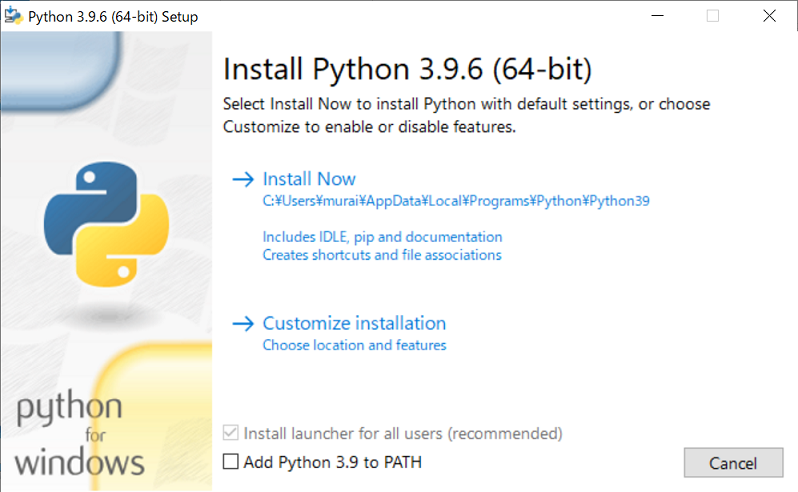
ダウンロードしたファイルを実行して、インストールをします。
特にインストール先の指定が無ければ「Install Now」を押すだけでインストールできました。
※今回は手動で環境変数PATHを設定しますが、
自動で環境変数PATHを設定したい場合は、「Add Python *** to PATH」にチェックを入れれば良いようです。
環境変数PATHを設定
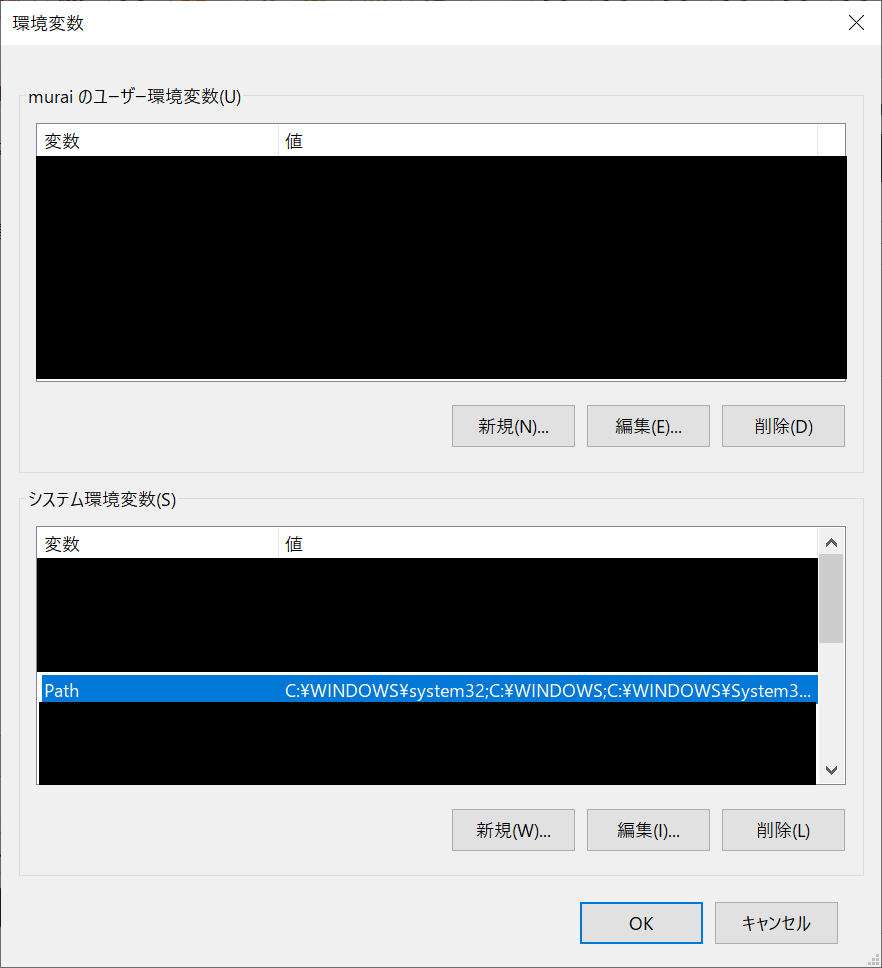
コマンドプロンプトでPythonのコマンドを実行するには、
環境変数のPATH設定を行う必要があります。
システム環境変数のPathを編集します。
先程インストールしたPythonのフォルダをPathに追加します。

コマンドプロンプトで「python -V」コマンドを実行し、Python のバージョンが表示されればOKです。

WEBスクレイピングに挑戦
必要なパッケージをインストール
今回はBeautifulSoupというライブラリを使ってWEBスクレイピングをします。
ただし、BeautifulSoupだけではHTTP通信機能がないため、requestsライブラリを合わせてインストールしていきます。
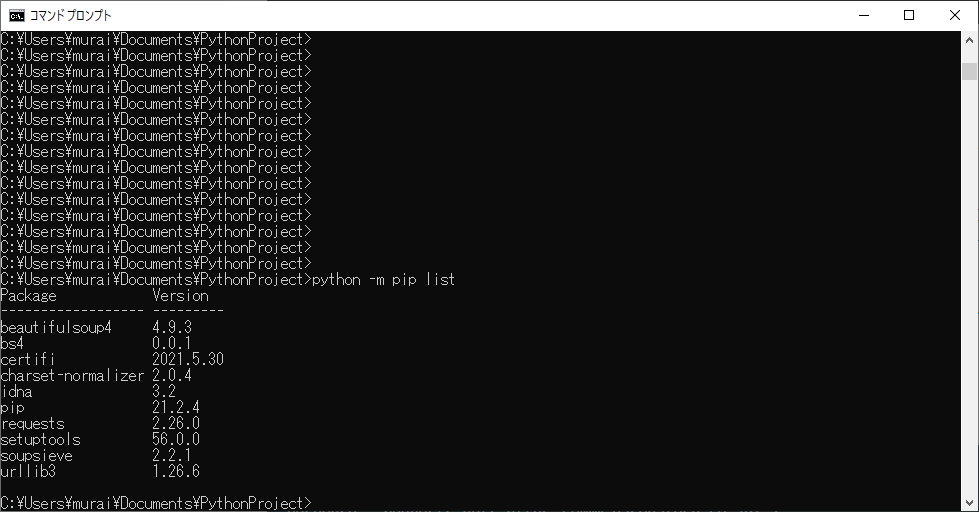
コマンドプロンプトで下記を実行し、ライブラリのインストールを行います。
「python -m pip install requests」
「python -m pip install bs4」
コマンドプロンプトで「python -m pip list」を実行し、リストの中に下記が表示されていればインストール完了です。
「beautifulsoup4」
「requests」
WEBスクレイピングするコードを書く
必要なライブラリがインストールできたので、
実際にWEBスクレイピングするコードを書いていきます。
試しに対象のURLのタイトルを取得するコードが書かれたPythonファイルを作成します。
今回はYahoo! JAPANのトップページを指定してみました。
C:\Users\murai\Documents\PythonProject\getTitle.py
import requests
from bs4 import BeautifulSoup
url = "https://www.yahoo.co.jp/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').get_text()
print(title)WEBスクレイピングしてみる
先程作成したgetTitle.pyを実行してみます。
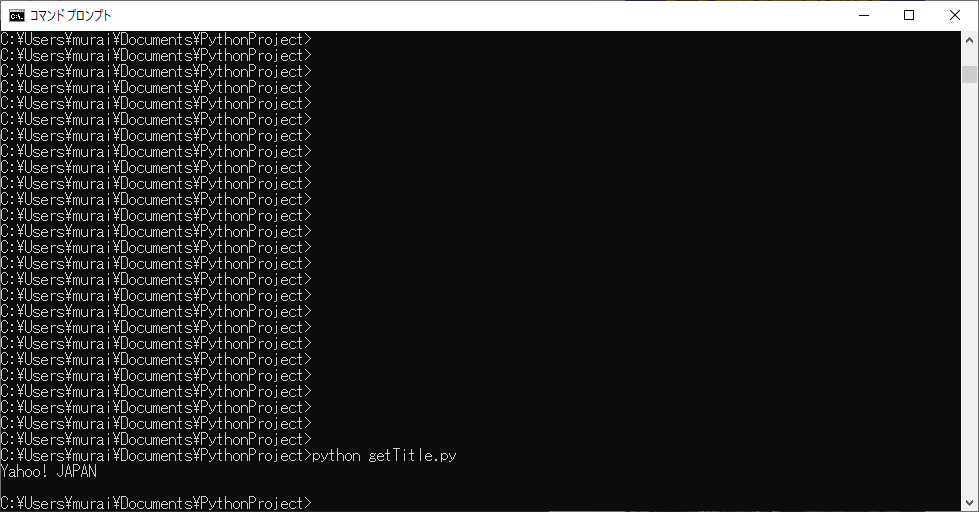
Yahoo! JAPANのタイトルが取得できました。
WEBスクレイピング成功です!
番外編:APIを使用してみる
せっかくPythonの環境構築をしたので、
WEBスクレイピングだけでなく、APIも使ってみようと思います。
普段はPHPでLaravelフレームワークを使った開発をしているので、
QiitaのAPIを使ってPHP関連の記事で、タイトルに「Laravel」とついている記事を抽出できるかやってみます。
※QiitaのAPIにはアクセス制限があるようですが、頻繁に取りに行くわけではないので、
今回は認証などは省きます。
APIを使用するコードを書く
API実行するコードなので、先ほどWEBスクレイピングで使用したBeautifulSoupは使いません。
jsonを扱うため、jsonライブラリとHTTP通信ができるrequestsを使用します。
C:\Users\murai\Documents\PythonProject\getTitleAndUrlRelatedLaravelByQiita.py
import requests
import json
res = requests.get('https://qiita.com/api/v2/tags/php/items')
jsondata = json.loads(res.text)
keyword = "Laravel"
for item in jsondata:
if keyword in item['title']:
print(item['title'])
print(item['url'])APIを使用してみる
先程作成したgetTitleAndUrlRelatedLaravelByQiita.pyを実行してみます。
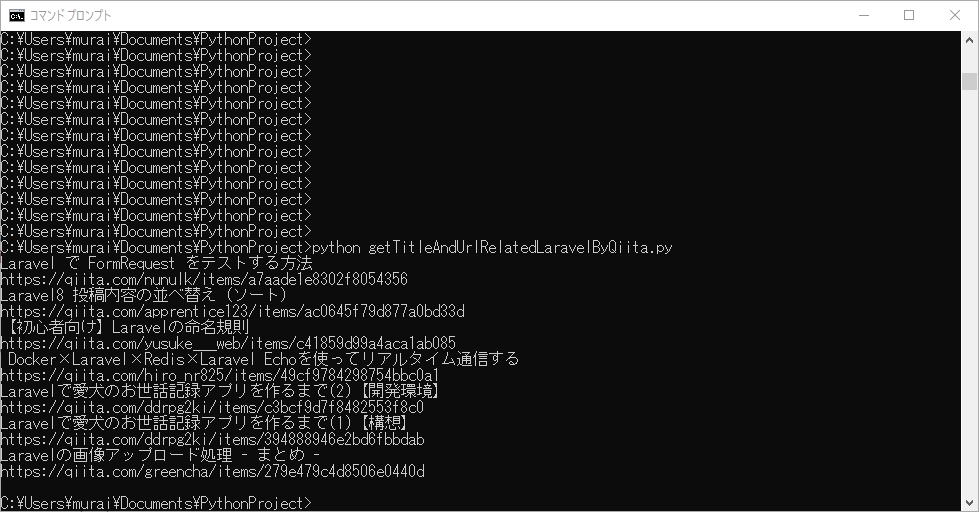
PHP関連の記事で、タイトルに「Laravel」とついている記事を抽出できました!
まとめ
以上、Pythonを使ってWEBスクレイピングとAPIの実行をやってみました。
正直なところ、これくらいの内容であればこんなに簡単に実装可能なのか。。。と驚きました。
ただ、WEBスクレイピングするたびにアクセスが走るため、
うっかり無限ループ処理などを書いてしまったら大変なことになるので、
そういったコードを書く場合は、かなり気を付けるべきだと感じました。
また、APIの実行がかなり簡単にできるので、
他の言語でWEBサイト構築をしていたとしても、
APIの使用処理だけはPythonで作るというのも悪くないかもしれないと感じました。