
jupyter lab でアニメ映画シリーズのデータセットを劇場公開数が多い順で可視化してみた!
はじめに
メディア芸術データベースのgithubに、劇場で公開されたアニメ映画のタイトル・公開年・配給元などの情報をJSONとしてまとめたデータセットが公開されていたので、このデータセットを利用して、アニメ映画公開数を作品毎に集計してどの作品が一番公開数が多いか可視化したい!と思いました。
以前の記事でpythonコードをブラウザ上で記述・実行できる jupyter notebook を入れてみましたが、その後続というか進化版であるjupyter labを今回は入れて、このデータセットを可視化します!
インデックス
python環境、jupyter lab環境がすでに構築済みの方は、環境構築は省略して、事前準備からご参照ください。
環境構築
まず python 環境を構築します。今回はM1 mac での手順になります。
- 実施環境
macOS Monterey 12.2.1(M1 mac)
- pythonインストール
M1 Macだと、python 3.9以上にしないと、pythonライブラリのpandas / numpy / matplotlib がインストールできませんでした。
デフォルトで入っているpythonバージョン(筆者は3.8.2)で、pipインストールしても、途中でエラーになりました><
ということで、python3.9以上を別途インストールします。
まず、Pythonのバージョン指定してインストールできるpyenvをインストールします。ターミナルを開き以下コマンドを実行します。
% brew install pyenv
pyenvインストールが完了したら、下記コマンドを実行し、インストールできるpythonバージョンリストを確認します。
% pyenv install --list Available versions: 〜省略〜 3.9.0 3.9-dev 3.9.1 3.9.2 3.9.4 3.9.5 3.9.6 3.9.7 3.9.8 3.9.9 3.9.10 3.10.0 3.10-dev 3.10.1 3.10.2 3.11.0a4 3.11-dev
ベータ版ですが3.11まであるようですね。
今回は、3.10.2をインストールします。下記コマンドを実行し、インストールします。
% pyenv install 3.10.2
下記コマンドを実行し、pyenvでインストールしたpythonのパスを設定します。
% echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bash_profile % source ~/.bash_profile % eval "$(pyenv init --path)"
下記コマンドを実行し、pythonバージョン3.10.2に切り替えます。
% pyenv global 3.10.2
下記コマンドを実行し、pythonのバージョンが切り替わっているか確認します。
% python -V Python 3.10.2
バージョンが「3.10.2」に切り替わっていますね。
- 仮想環境作成
次にjupyter lab作業用の仮想環境を用意します。作業用フォルダーなど任意の場所で、下記コマンドを実行します。
% python -m venv my_jupyter_lab
これで my_jupyter_labフォルダー内にpythonの仮想環境が構築できました。
仮想環境で作業するため、作成した仮想環境をアクティブ化します。
% cd my_jupyter_lab % source bin/activate (my_jupyter_lab) my_jupyter_lab %
これで仮想環境で作業ができる状態になりました。
- jupyter lab含むライブラリインストール
それでは、pipコマンドで、必要なライブラリをインストールします。
jupyter lab も、pipコマンドインストールできます。
(my_jupyter_lab) my_jupyter_lab % pip install ijson (my_jupyter_lab) my_jupyter_lab % pip install numpy (my_jupyter_lab) my_jupyter_lab % pip install pandas (my_jupyter_lab) my_jupyter_lab % pip install plotly (my_jupyter_lab) my_jupyter_lab % pip install jupyterlab
インストールできたか確認します。
(my_jupyter_lab) my_jupyter_lab % pip list Package Version -------------------- --------- 〜省略〜 ijson 3.1.4 〜省略〜 jupyter-client 7.1.2 jupyter-core 4.9.2 jupyter-server 1.13.5 jupyterlab 3.3.0 jupyterlab-pygments 0.1.2 jupyterlab-server 2.10.3 〜省略〜 numpy 1.22.2 〜省略〜 pandas 1.4.1 〜省略〜 plotly 5.6.0
これで環境構築はできました。
事前準備
- データセットダウンロード
今回はgithubで公開されているメディア芸術データベースにある、「an210:アニメ映画シリーズ」のデータセットをダウンロードします。Downloadから、JSONファイルをダウンロードします。
ちなみに、データセットは、2010年代までのデータで、2020年代のデータはまだ反映されていないようでした。最新データも早く更新されると良いですねー。
ダウンロードしたファイルを、上記で作成した仮想環境のディレクトリーに datasetディレクトリーを作成して、格納します。
- データセット加工
ダウンロードしたファイルを集計しやすいように加工しておきます。
オリジナル作品名(原作名)を、劇場タイトルから抽出して設定します。
今回は、公開数が多そうなタイトル(と自分が好きなタイトルも^o^)をピックアップして抽出します。
公開年を10年間隔で集計したいので、screeningYearカラムを追加します。公開年が未設定のものがあるので、集計欠損避けるため、’情報なし’と設定します。
コードは下記のようにしました。
import glob
import ijson
import json
import numpy as np
import os
import pandas as pd
import re
import datetime
# 必要なカラム
COLS_AN210 = [
'label',
'originalWorkCreator',
'startDate',
'publisher',
]
PICKUP_ANIMATION = [
'ドラえもん',
'名探偵コナン',
'クレヨンしんちゃん',
'ONE PIECE',
'DRAGON BALL',
'アンパンマン',
'ガンダム',
'うる星やつら',
'らんま1/2',
'SLAM DUNK',
'ポケットモンスター',
'プリキュア',
'BLEACH',
'NARUTO',
'ゲゲゲの鬼太郎',
]
# jsonデータ読み込み
def read_json(path):
with open(path, 'r') as f:
dct = json.load(f)
return dct
# 原作者情報加工
def format_original_work_creator(workCreator):
if workCreator is np.nan:
return None
if type(workCreator) is str:
# 空白など入っているのでここで削除しておく
table = str.maketrans({
v: '' for v in ['\u3000',' ']
})
workCreator = workCreator.translate(table)
return workCreator
# ピックアップした作品をlabel名から設定する
def format_work_name(label):
if label is np.nan:
return None
for x in PICKUP_ANIMATION:
result = re.findall(x, label)
if result:
return x
return None
# 公開年設定
def format_start_year(startDate):
if startDate is np.nan:
return '情報なし'
tdatetime = datetime.datetime.strptime(startDate, '%Y-%m-%d')
year = tdatetime.year
if year < 1980:
startYear = '1970年代'
elif year >= 1980 and year < 1990:
startYear = '1980年代'
elif year >= 1990 and year < 2000:
startYear = '1990年代'
elif year >= 2000 and year < 2010:
startYear = '2000年代'
elif year >= 2010 and year < 2020:
startYear = '2010年代'
elif year >= 2020 and year < 2030:
startYear = '2020年代'
return startYear
# datasetパス
datasetPath = './dataset/metadata_an-col_an210_json\metadata_an-col_an210_00001.json'
# dataset読み込み
an210 = read_json(datasetPath)
# @graphからアニメ劇場版シリーズのデータをカラム絞って取得
dfAn210 = pd.DataFrame(an210['@graph'])[COLS_AN210]
dfAn210['originalWorkCreator'] = dfAn210['originalWorkCreator'].apply(
lambda x: format_original_work_creator(x))
# オリジナル作品名設定
dfAn210['workName'] = dfAn210['label'].apply(
lambda x: format_work_name(x))
# 公開年設定
dfAn210['screeningYear'] = dfAn210['startDate'].apply(
lambda x: format_start_year(x))
# ピックアップ抽出後のデータ
outputDf = dfAn210.dropna(subset=["workName"])
# 加工データをcsv保存
outputDf.to_csv(os.path.join('./dataset/', 'animation_movies_dataset.csv'), index=False)
作成したコードを実行します。ファイル名は prework.py で作成しています。
(my_jupyter_lab) my_jupyter_lab % python prework.py
実行すると、datasetディレクトリーに animation_movies_dataset.csv という名前で以下の内容のCSVファイルが作成されます。
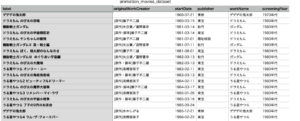
このCSVファイルを使用して jupyter labでグラフ化します。
アニメ映画公開数を作品毎に集計して jupyter lab で可視化してみよう!
- jupyter lab起動
下記コマンドで jupyter lab が起動します。
(my_jupyter_lab) my_jupyter_lab % jupyter lab
コマンド実行すると、ブラウザ画面が起動します。
- ノートブック作成
python3 を選択し、 notebookを作成します。
作成したノートブックは、untitleになっているので rename します。
ファイル名を選択して右クリックし、rename でファイル名を変更します。
作成したノートブックに下記コードを記述します。
import pandas as pd
import itertools
import plotly.express as px
RENDERER = 'plotly_mimetype+notebook'
# グラフ描画
def show_fig(fig):
fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
fig.show(renderer=RENDERER)
# データ欠損を0で補足
def resample_workname_and_screeinig_years(df):
df_new = df.copy()
workNames = df['workName'].unique()
screeningYears = df['screeningYear'].unique()
for workName, screeningYear in itertools.product(workNames, screeningYears):
df_tmp = df_new[
(df_new['workName'] == workName)&\
(df_new['screeningYear'] == screeningYear)]
if df_tmp.shape[0] == 0:
df_add = pd.Series(
{'workName': workName,
'screeningYear': screeningYear,
'count': 0},
index=df_tmp.columns)
df_new = df_new.append(df_add, ignore_index=True)
return df_new
df = pd.read_csv('./dataset/animation_movies_dataset.csv')
# 年代別で公開数をカウント
df_plot = df.groupby('workName')['screeningYear'].value_counts().\
reset_index(name='count')
df_plot = resample_workname_and_screeinig_years(df_plot)
# 公開数合計で降順ソート
workNames = list(df.value_counts('workName').index)
df_plot['sort'] = df_plot['workName'].apply(
lambda x: workNames.index(x))
df_plot = df_plot.sort_values(['sort', 'screeningYear'], ignore_index=True)
fig = px.bar(df_plot, x='workName', y='count', color='screeningYear',
color_discrete_sequence= px.colors.diverging.Portland, barmode='stack', title='アニメ劇場シリーズ公開数')
fig.update_xaxes(title='アニメ作品名')
fig.update_yaxes(title='劇場シリーズ公開数')
show_fig(fig)事前準備で作成した animation_movies_dataset.csv を読み込んで、作品毎に公開年でグループ化し、公開数合計が多い順でグラフ描画しています。
それでは、コードを実行します。実行ボタンを押下することでコードが実行できます。
するとコードの下にグラフが描画されます!
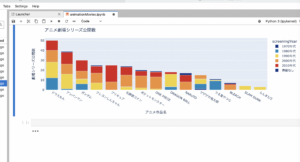
ドラちゃんダントツですね!次に、アンパンマンと国民的アニメが上位に来ていますね。ガンダムもシリーズが多いため3番目になっています。クレヨンしんちゃんは、1990年代から一定数の公開になっていて映画シリーズが根強い人気なのが見えてきますね。
上位を除いて各年代で見てみると
1980年代は うる星やつら が公開数が多い(水色部分)
1990年代は DRAGON BALL が公開数が多い(黄色部分)
2000年代は ONE PIECE、ポケモン、名探偵コナンが公開数が多い(オレンジ部分)
2010年代はプリキュアが圧倒的に公開数が多い(赤色部分)
とその時代で人気のアニメ作品が見えてきますね。
おわりに
今回は、アニメ映画シリーズのデータセットをjupyter labで、劇場公開数が多い作品を集計して可視化してみました。こういうデータセットがあると、興味も湧きますし、色々試してみたいと意欲も湧きますね!